Days 40-43: Group Project
In possession of half a dozen @bagelsaurus13 bagels and the @MongoDB docs. It's (group) project week at @GA_boston!
— RebekahHeacockJones (@rebekahredux) October 15, 2016
The third project for General Assembly was a group project. Each group received a prompt and roughly five days (including the weekend) to execute on it, starting Friday night on Week 8.
Our prompt:
Make an app that can be used to create custom surveys (for instance, asking “what should we eat for lunch today?” or “On a scale of 0-5, how well did you understand what we just learned?”) and collect the responses on a dashboard for that particular survey.
Data Modeling
One of my group members (thanks, KTab!) suggested that we build an online invitation tool instead—the underlying principles (ask a question, collect responses from different users) are the same, but the premise felt a little more fun. We drew up a quick ERD in LucidChart (which is becoming my favorite tool for data modeling) and were feeling pretty good about it:
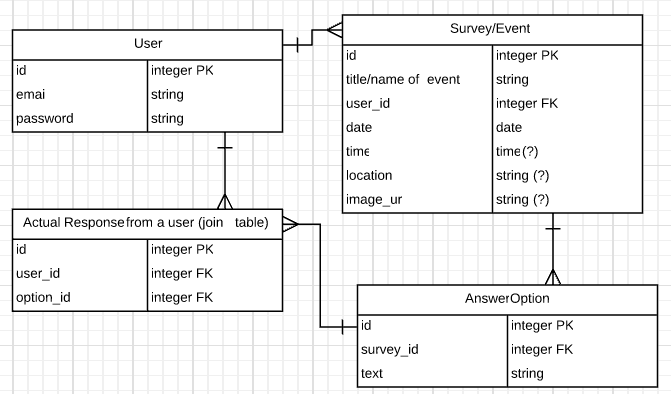
So pretty! See all those beautiful tables? and fields? and carefully documented relationships?
That’s about when we remembered we were required to use MongoDB & Mongoose instead of a SQL database. (Other requirements: use Express to build a RESTful API, built a JS-based client app to consume data from that API, include user authentication, include all CRUD actions, write user stories, build wireframes, use git/GitHub as a team.)
Awkward. Mongo doesn’t have tables or relationships or models. Mongoose lets us add models and relationships (-ish), but there are still no tables.
We attempted to convert our relational model into a rough sketch that approximated something more document-friendly:
User {
_id,
email,
password,
}
Survey {
user_id,
_id,
title/name,
date,
time,
location,
image_url,
options: [
{ id, text },
{ id, text },
]
}
// less sure about this
Response {
option_id,
user_id
}
This more or less attempts to map our tables onto documents. Which, as far as I can tell, is rarely the best approach: trying to convert a relational data model for use in a NoSQL database seems like it only leads to heartache.
On Friday evening, our group had a long talk with our instructional team about our model, in which they attempted to convince us that what we should be storing as a response—instead of links to an option id and a user id—is a full copy of an event/survey, with the options array replaced by whatever the user chose for their answer. And we could forget
Cue all the feelings of ickiness about data duplication and potential out-of-sync-ness and, again, data duplication. Data duplication is also called data denormalization: this is good for reducing the number of queries needed; it also reduces number of write operations needed: you only need to write to one document to affect lots of data. But still: THIS FEELS SO DIRTY.
Part of the argument was that storing a full copy of an event/survey (which I’ll refer to as an “event” from here on out) inside of a response means that a user’s response to a question isn’t affected if the event owner changes the event. In both our initial relational model and the model above, an event owner could change the question associated with an event from something like “Are you coming?” to “Do you eat hamburgers?” A vegetarian reader who had RSVP-ed yes could suddenly find themselves having committed to eating meat. Storing an entire copy of the event as it was when the user responded inside of the user’s response means that a response and a question are never out of sync. This is a good thing!
What’s not as good: events and responses are never reliably in sync. (I’m intentionally setting aside the pros and cons of letting a user edit an event after people have already responded—this is weird functionality that has a lot of potential issues, both technical and social.) This means that response data can’t as easily be counted and presented.
After some back and forth, we decided to go with this approach. We rewrote our data outline to look like this:
User {
_id,
email,
password,
username,
}
Event {
_id,
_owner (references user id),
name/title,
location,
date,
startTime,
endTime,
description,
questions: [
{
text: Are you coming?,
options: [yes, no, maybe]
},
{
text: Which dinner option do you want?,
options: [fish, chicken, pasta]
}
]
}
RSVP {
_id,
_event (references event id),
_owner (references user id),
questions: [
{
text: Are you coming?,
answer: yes
},
{
text: Which dinner option do you want?,
answer: pasta
}
]
}
I’m still pretty uncomfortable with this. A couple of things I’m still working out:
- Does copying (“serializing”) an event into a response make sense? Duplicating event data (things like title, location, etc.) means that displaying a single RSVP requires only a single query to the RSVPs collection, rather than a query that accesses both the RSVPs and the events collections. It also means that if a user changes anything about an event—updates the description, for example—that change isn’t automatically propagated over to each corresponding RSVP. It would be possible, I think, to write code that updates each RSVP when an event is updated, but a) that’s potentially database-intensive in a way that feels dirty to me; and b) that kind of defeats the point of serializing data in the first place.
- Does allowing a user to edit an event after it has received RSVPs make sense? I can see arguments for an against this. We currently have a warning message on the edit page that lets event owners know that changing data related to questions & answers might affect the responses they see, but this is a human (not a technical) way of handling things, and it doesn’t feel entirely sufficient.
- If a user does edit an event and change the associated questions/answers, what happens to someone who’s already responded? Does their data “count”? Should their answers still be reported to the event owner/as part of the event? We’re currently looping through the questions/answers on the event and tallying up matching answers in any associated responses, which means that only responses matching the current version of the event data get counted. Again, this doesn’t feel like the optimal approach.
- In general, tallying response data feels less efficient: we have to locate an event, locate all of the responses, and then inspect the data within the event to find the current questions and answer options. We then have to compare that data to each response and evaluate whether there’s a match. In a relational database, we’d need more queries, but it would be much easier to get counts. We’re also doing all of this based just on string comparison, rather than on database ids, which makes me…sort of itchy. (This is related to, but not entirely the same as, my question about editing events, above.)
- We’re currently leaning on Mongoose’s
.populatemethod to retrieve all of the RSVPs that belong to an event when we get an event. After reviewing the code, it looks like I for some reason also set up a virtual property on the Event model that gets all of the RSVPs. I’m pretty sure this is redundant/not actually doing anything—adding this to my list of future revisions. Also, we’re populating the RSVPs for an event in order to do two things: 1) check RSVPs and do some filtering so a user isn’t given the option to re-RSVP to something they’ve already responded to; and 2) tally up responses. It looks like we could be using Mongoose’s field name syntax to only grab the user ids and the question/answer data, which would help streamline things, which makes me happy. - This is less “a thing that makes me uncomfortable” and more “a thing I’d like to do in the future,” but right now, we’re not handling different question types very well: responses are set up to only hold a single answer for a question, and questions in an event have an array of possible answer options. This doesn’t work well for things like open-ended questions, multiple answer questions, etc. I’d like to come back to this and think about how to better handle a range of question types.
- We got our API up and running over the weekend (nothing like a Bagelsaurus-fueled Saturday marathon coding session) and met with the instructors again on Monday for feedback. They brought up another possible approach we hadn’t considered: setting up a separate “statistics” controller in Express to handle population and data tallying. This would involve making a query to the events collection for the event, then making a secondary request to a stats route (which would then presumably query the RSVPs collection?), and *then* building out whatever data display we wanted. This isn’t super efficient, but it is clean: what I took away from the conversation is that it’s a bad idea to have the event & RSVP models talk to each other inside of the model (like we are with the virtual property)—we want to avoid having a “junk drawer” model in the app that essentially pulls in data from all of the other models. To be totally honest: we considered this idea for a minute and decided to forge on without implementing it because the API was functional, it was Monday, and we had three days to build the client app.
After our feedback meeting, we took away a list of to-dos related to our API:
- Make sure to delete all RSVPs associated with an event before deleting the event. My understanding is that because we’re using Mongo and Express, the only way to do this is manually—there’s nothing like Rails’
dependent: :destroy. - Build a way to show all events to a user that don’t belong to the user AND to which a user hasn’t RSVPed (a list of all RSVP-able events for a user).
The first of these was fairly trivial: in the destroy method in the events controller, first remove/delete all associated RSVPs, then delete the event.
The second of these was more difficult. We attempted this:
Event.find({ $and: [ { _owner: {$ne: req.currentUser._id } }, { 'rsvps._owner': { $ne: req.currentUser._id } } ] } )
Which did not get us what we want: you can’t directly query populated data like this. On the advice of our instructors, we ended up finding all events where the owner is not the current user, then using .foreach() to loop through each rsvp for each event and determine whether the current user owns any of them (whether the current user has already rsvped for the event). The logic was sound here, but it took us longer that I want to admit to process that MongoDB ids are not strings. Doing a comparison—even a loose one—between rsvp._owner and req.currentUser._id was getting us nowhere until one of my groupmates (thanks, Jaime!) suggested that we call .toString() on the ids. Success!
A thing I learned the hard way today: MongoDB ids are not strings. #strictequality #thesamebutnotthesame #headdesk
— RebekahHeacockJones (@rebekahredux) October 18, 2016
Now that we’re not under the wire, I’m realizing that Query#populate might have gotten us closer to what we wanted, and Query#select the rest of the way, without having to loop through all of the data. I’d like to go back and try this—if it works, it would definitely be a cleaner approach.
Client-side App
With our API all squared away, we spent Tuesday and Wednesday working on the front end. This was fairly straightforward—it didn’t differ too much, structurally speaking, from the front ends we had all built for our second projects.
The two most difficult pieces were both tied to questions and answers: figuring out how to count up and display response data, and figuring out how to correctly display and gather question & answer data from forms. (In Boston, GA offers a “get form fields” JS script that extracts data from form fields and, based on the name attributes of each field, formats it as a JavaScript object. This is usually sufficient, but I couldn’t quite manage to figure out how to name our inputs in order to end up with an array inside of an object that also contains a property that’s a string, and have of that end up in another array that’s inside of an object. I eventually ended up with input fields for the answer options that are named event[questions][0][options][], but I haven’t yet worked in the ability in Handlebars to generate multiple questions (event[questions][1][options][], etc….)
We started with a pretty low bar, initially: event creators would have no say over questions and answers. Instead, all events would have a single question (“Are you coming?”) with three potential answers (“Yes”, “No”, and “Maybe”). We wrote our forms (using Handlebars templates) and our “tallying” code to handle this case, and then decided to expand incrementally: first by writing more flexible tallying code that would match up the event’s question and answer options against the responses, and then by allowing event creators to edit a single question with three required answer options.
The next step—on my list of to-dos—is to give event creators the power to add multiple question possibilities with variable numbers of answers. Our API is set up to handle this, but the front end doesn’t yet have the flexibility to add/remove the necessary form fields to expand/contract the set of questions and answers.
A third interesting and kind of tricky piece was handling date and time formatting between Mongo, form fields, and display. I ended up writing a tiny library of functions to handle this for us, and then—during our presentation—learned about Moment.js. Next time!
Aesthetics
Our design came down to the wire a bit—we prioritized, I think rightly so, API and UI functionality over shine. That said, we managed to get in a few custom colors/fonts and a background image for the home page. This is definitely on the “come back to” list—we have a long list of ideas (uploading header images for events! changing an invitation’s color scheme based on those images! offering different invitation designs! fully responsive design! among other things) we’d love to implement going forward, but as of Wednesday evening, we had a fully functional product with an acceptable design.
Happening

Happening: Online invitations for events big and small
Happening API on GitHub
Happening client on GitHub
Day 44: Whiteboarding
We spent Friday split into our new (and final!) squads, practicing interview questions with the instructors, with our course producer, on CodeWars/HackerRank/Interview Cake, and with a group of GA alumni who came in during the afternoon and ran mock whiteboard interviews with us. It’s not exactly news, but technical interviewing is a totally different skill than building web applications. I think I like the data side of things the best (see: this post), but my current sense of the industry is that to move decisively in that direction, I’ll need to get much better at “traditional” computer science skills and concepts, including algorithmic thinking, pattern recognition, and math. In particular, I’d like to improve my ability to draw upon this knowledge quickly during interviews. On the advice of a friend, I’m working my way through Cracking the Coding Interview and spending as much time as I can on HackerRank.
Friday was intense, especially coming off of project week, but it was also fun. I’ve always loved tests, and the questions I was asked—which ranged from “design a Monopoly game” to “what is a closure” to “what’s your favorite programming language and why?” to good old fizzbuzz—stretched my brain in different directions pretty rapidly, which was good practice.
Just three more weeks to go!