
Week 12 was strange for many reasons: it was the final week. It was a short week—we had Friday off because of Veteran’s Day. Tuesday was Election Day, which….
It was also our final project week, which meant I spent most of the week sequestered in one of GA’s shiny and tiny new conference rooms with coffee and Ember and Rails. Using Ember for our final projects was optional, but I jumped on the chance because a) client side routing; b) I wanted the practice; and c) it sounded fun.
Regarding that last point:
I chose to use Rails for the backend (instead of Node/Express) because it’s a fairly natural pairing and because we had roughly a week to build the project, and I’m more comfortable with Rails than Express at this point.
It’s been two months exactly since I presented my project—sorry for anyone waiting with bated breath to read about my final week at GA—so in the interest of finally getting a post up, instead of doing a detailed blow-by-blow of that week, I’m going to cover the highlights. If there’s anything that piques your interest, leave a comment or get in touch via Twitter/etc., and I’m happy to expound!
Project Planning
When I first seriously starting learning JavaScript, beyond copying & pasting random code to hide and show things on web pages when I was a kid, I started playing around with the idea of building a tool that would generate a random pattern for a quilt, made out of squares and triangles of different colors. This was inspired by the desire to build something super visual, by Libs Elliott’s stunning and unbelievably cool work to generate much better/more intricate patterns with Processing, and by my own interest in quilting.
My first attempt at building this resulted in 335 lines of JavaScript in a single file, nearly 200 of which were inside of a single onclick event. Also: when I abandoned it in November 2015, it didn’t work, and my commit messages were shoddy enough/my use of branching nonexistent such that I couldn’t remember when it last worked and what I had done to break it.
I decided to take this opportunity to revisit the idea and expand upon it, adding the ability to register, to save/favorite different patterns, and to create “projects” associated with specific patterns that would let users write up notes on actually making the pattern into a quilt and photos of the process/the finished quilt.
Prework: File Uploads with Paperclip and Rails
I started by working on photo uploads: we had briefly covered how use Multer/Express/AWS S3 to upload photos and store URLs to a database, but I needed to apply this knowledge to a Rails API and to Ember. I knew I would need to re-scope my project idea if I couldn’t get uploads to work, so given the tight project timeline, I decided to focus on this first, give it a day or so, and move on if I hit too many roadblocks.
I set up the API and scaffolded a very basic “pattern” resource—at this point, I was thinking that I would need to store the generated pattern as an image (I’ll come back to this later). Following along with a General Assembly repository on using Paperclip that’s a couple of years old/out of date, and is no longer being taught by GA Boston, I installed Paperclip and ImageMagick to help with uploads through Rails, then wrote a curl script to test whether I could POST image data to the API without yet storing it in S3. I had to write a slightly different script than the ones I had been using to send JSON data through POST requests; this Stack Overflow post on data types helped.
I installed the aws-sdk gem, which Paperclip uses to store files on S3, and added the necessary AWS config variables (s3 region, bucket, access key ID, and secret access key) to my .env file so that I could use them in my config files. From there, I used curl to test the upload process and make sure that files were being successfully stored in S3 and the URL saved in my database.
Success! I wrote up my process as an issue on the GA Paperclip repo for a few other students who were hoping to do the same thing in their projects, then moved on to working with Ember.
This was…frustrating. After spinning up a very basic Ember project using the Ember CLI, I tried multiple different plugins/components/guides, including ember-data-paperclip, ember-cli-form-data. In the end, I just wrote a basic HTML form, set the enctype to multipart/form-data, and used JavaScript to get the form data by the form’s ID instead of trying to use any Ember fanciness (though apparently using event.target instead of the ID is a better approach?). I also wrote a short custom upload service to send the AJAX request in the correct format.
This took two afternoons, mostly working solo/Googling like mad, but also checking in with one of the GA instructors, who was also attempting to crack this challenge. (Not at all #humblebrag: proud to say I solved it first!) This was one of my first real moments going “off script” at GA, and it was frustrating and awesome and confusing and wonderful. It’s one thing to take a lesson with step-by-step instructions and well-documented code and apply it to your own very similar project; it’s another thing entirely to take snippets of tutorials and gem/plugin docs and a rough sense of what you want to do and make it work. I know this problem isn’t a gigantic one—many, many people have successfully solved it, and I’m sure there are much better, cleaner ways of approaching it than the one I ultimately took—but it was cool to find my own way through the fog.
Resources in Ember & Rails
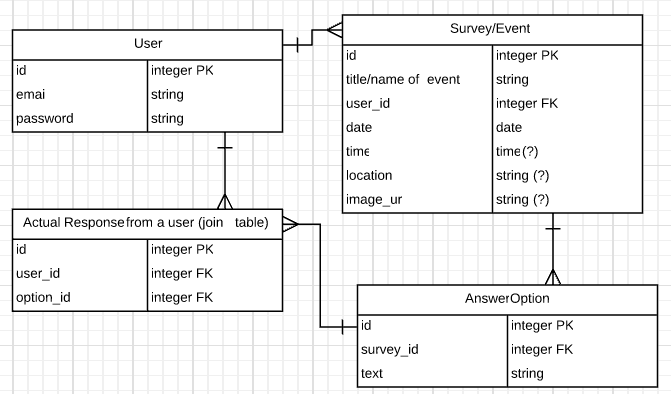
Saturday afternoon was spent on Ember: integrating authentication and generating some basic routes/models/components. In the process, I switched from using a simple join table and has_and_belongs_to_many to connect Users and Patterns to building a Favorites resource and connecting Users and Patterns using has_many :through—this was prompted by a question I raised about how to do a post to this join table without having a separate, named resource; a good list of the arguments in favor of has_many :through is in the response here.
While working to get data transfer happening smoothly between Ember and Rails, I ran into some confusion around serialized data for many-to-many relationships. This was solved by tweaking my models in Rails; Ember likes to receive IDs (instead of full JSON records) for associated data (details on how to do this are in this issue).
Quilt Pattern Generation
By Saturday evening, I was ready to start tackling pattern generation. I decided to use the (aptly, if coincidentally, named) Fabric.js library to help with this because it makes exporting data from an HTML5 canvas in different formats super easy. Fabric is so fun to work with!
I also got the chance to write another, more detailed custom service in Ember to handle the pattern generation. There are a number of ways in which I’d like to continue refining this, including streamlining the code that draws each individual quilt block (a square or one of four different triangles), adding a way to calculate the total fabric yardage needed for a quilt based on the final number of blocks of each size and color, and letting users choose their own color schemes. That said, this was an amazing opportunity to revisit old code I’d written and figure out how to make it better. I cut the size of the file roughly in half, with the longest method around 50 lines (STILL VERY LONG, but definitely not 200!).
In the process, I also realized that I don’t need to upload anything to S3 for patterns—no need to store these as images; I can just store them as SVG strings which are smaller, load faster, and are easier to scale for different screens and views. Hooray! (Also: I feel like I’ve come a long way with SVG.)
Ember (Days 54-56)
One of our instructors warned us that working with Ember would be an emotional rollercoaster, and HOO BOY was that true. I cycled back and forth between “I LOVE THIS” and “I HATE THIS” more times than I can count. Two months later, I think this was largely because I was trying to do a bit more than was reasonable within my time frame, I was basing my project off an Ember repo that was given to us that had auth built in (which was nice) but also a pretty intense pre-set template of nested components/styling choices that I had to figure out how to dismantle to get what I wanted out of the project (which is still not 100% mobile responsive, which irks me but not enough that I’ve gotten around to fixing it), and, to be honest, because it was election week. Wednesday was a rough day.
I don’t have a ton to report here, which I realize makes for a less than brilliant blog post, but I will leave a couple of notes/thoughts here:
An issue I wrote on how to write a component that does the same action in multiple different parts of the app without repeating that action’s code in multiple different Ember routes. The advice I got was to inject the Ember store into the component, which allows the action to happen at the component level instead of passing it up to multiple different routes to happen there. This is unconventional at best (and some might say a terrible idea), but was an interesting way of getting rid of a ton of redundant code.
GA provides guidance on how to deploy our projects to the web using Heroku (for our Rails APIs) and GitHub Pages (for our client side code). The deployment instructions were oftentimes a bit shaky—I suspect this is the product of having so many different cohorts and instructors and of rapidly changing technology. I ended up writing a condensed, shorthand version of the Rails & Ember deployment guides for my own use that addressed some of the errors/missing information in the existing guides, and then shared it with enough friends that I ended up posting it as an issue for everyone in the cohort.
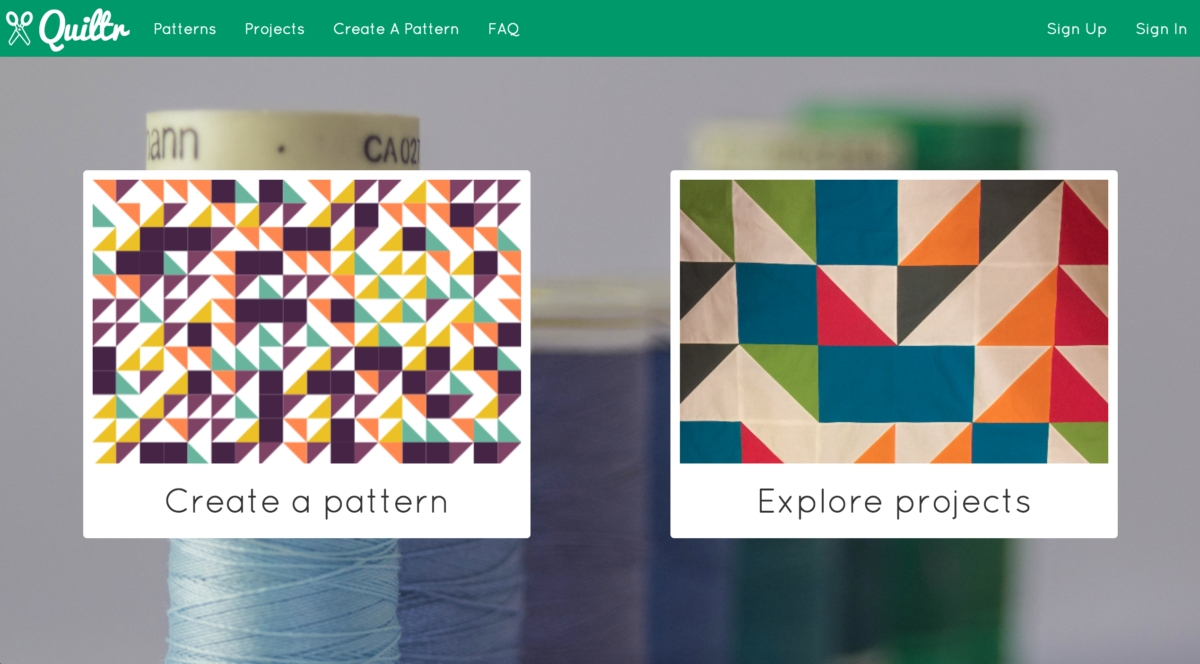
Lastly: huge thanks goes to my mom, who took the time to beta test Quiltr and actually made a quilt based on one of the patterns I generated, which is featured on the app’s home page. This made my presentation at least 10x cooler than it would have been otherwise.
Quiltr
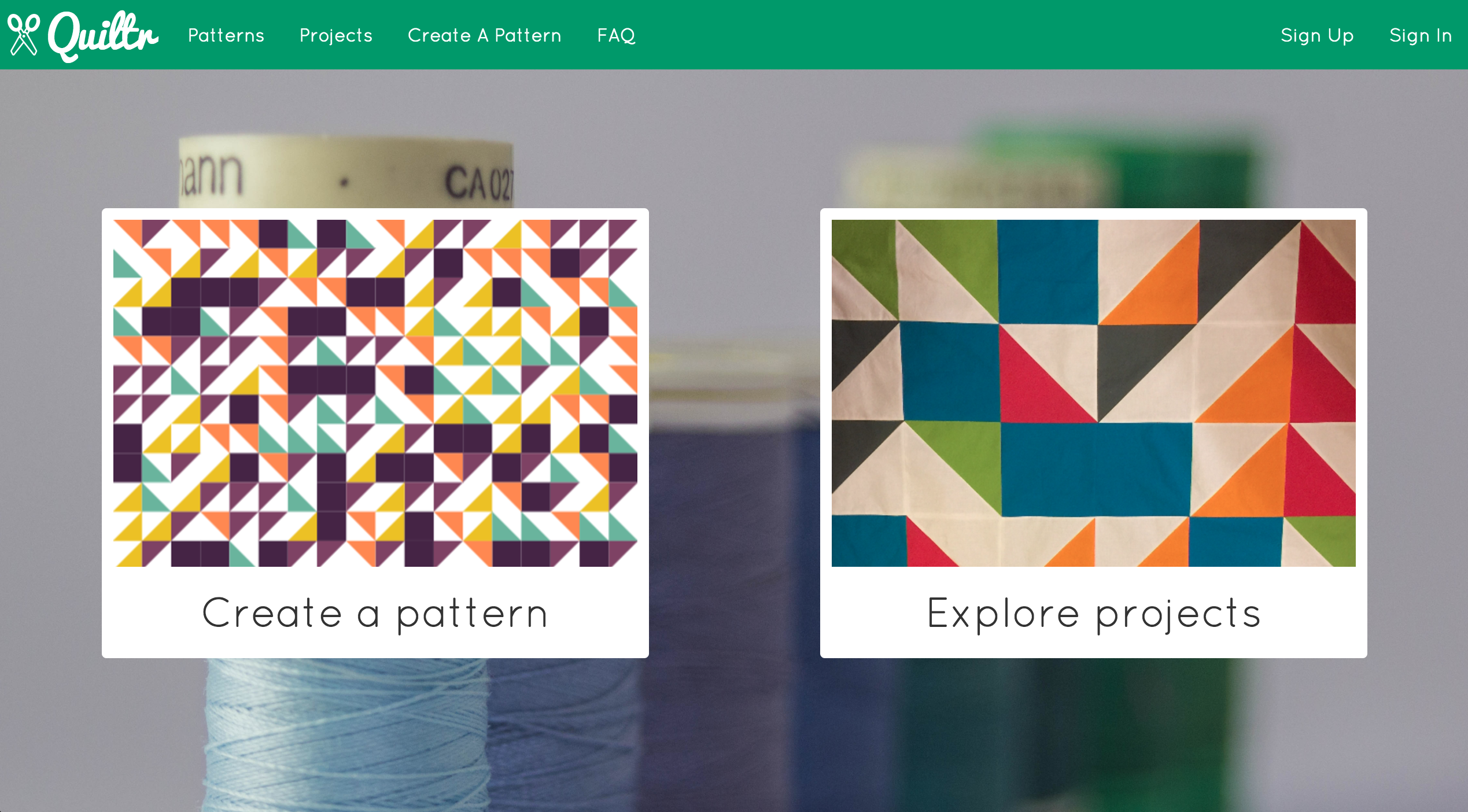
Create patterns. Make quilts. Be inspired.
Live app: https://rhjones.github.io/quiltr/
Live API: https://quiltr.herokuapp.com/
Ember repo: https://github.com/rhjones/quiltr
Rails API repo: https://github.com/rhjones/quiltr-api