Days 30-32
The first three days of Week 7 were devoted to our projects: Monday and Tuesday were work days, and Wednesday was for presentations. If you want a blow-by-blow of project two, I wrote up my daily dev log here.
While working on my project, I had an interesting conversation with one of the GA instructors about the API we use for our first project (Tic Tac Toe). I built a feature for my version of the game that gets all of a user’s prior game history when they log in and goes through each game that’s marked as “over” to calculate whether the game was a win, loss, or tie. These stats are tallied and displayed at the bottom of the window, and are updated as the user plays new games.
It doesn’t take a long time to calculate these stats—the logic isn’t terribly complicated, the entire package of data is pretty small, and, seriously, how many games of Tic Tac Toe could one person ever want to play? But I’ve been thinking about how much easier this process would be if, at the end of a game, we could just store the winner (or “tie”) on the server. That would let us avoid re-calculating the winner for each game just to get a stats counter.
After I made my pitch, I got a quick introduction to memoization, which is when you store data that takes some time to calculate on a server, so you can retrieve it rather than recalculating it each time. The key point we covered: memoization without validation can be dangerous. It would be easy to mark a player as the winner without the game being over and/or without that player having won. Also, for Tic Tac Toe, it’s not really a big issue, as it’s not that computationally expensive to re-tally the stats each time (it’s also, as was pointed out to me, a good exercise for us). Another point: memoization involves a tradeoff between time (to recalculate) and space (to store extra data on the server). Lastly: this is still a bit above my paygrade as someone relatively new to the field. But it’s cool to be thinking about!
Another couple of things that came up during project presentations that I want to remember:
- A handful of people recommended Bootsnipp for examples of good uses of Bootstrap for specific UI elements (things like testimonials or five-star ratings).
- One person made the best wireframes using Balsamiq. I experimented with creating my wireframes in LucidChart, since I had already sketched out my data relationship model there, but I ended up drawing them by hand, which was faster and easier. But those Balsamiq wireframes…they were gorgeous.
- It’s a bad idea, optimization-wise, to include an entire font in your project if you’re only going to use a couple of characters (for a logo or an icon, for example). It slows down load times, especially on mobile; it’s better to make a .png of what you need and use that instead. Guilty as charged—going to try to do better next time.
Day 33
After a quick review of distributed git workflows (our next project is a group project), we jumped back into JavaScript to talk about this.
Back to JavaScript today at @GA_boston. #thisjokes #whatsthis pic.twitter.com/WEs5MGbP9Q
— RebekahHeacockJones (@rebekahredux) October 6, 2016
It’s notoriously difficult to understand.
Actual code example from the @MozDevNet docs on “this”: https://t.co/Cuf6FT6Sir pic.twitter.com/4uLqiFIsDb
— RebekahHeacockJones (@rebekahredux) October 6, 2016
Though I think (hope) I’m starting to get a better handle on it. We talked about the “four patterns of invocation” (described by Douglas Crockford in JavaScript: The Good Parts):
- Function Invocation Pattern: If you call a function in the global namespace,
thisrefers to the global object. In the browser,thisis the window; in Node, you’ll get the node object. Note that this is not true if you’re using'use strict'—strict mode disablesthisfrom pointing to the global object; instead, it points toundefined. - Method Invocation Pattern: If you call a function on an object (
dog.bark()),thisrefers to the “host object” (the object on which you called the method). Inside ofbark(),thiswill bedog. - Call/Apply Invocation Pattern: You can use
.call()and.apply()to pass an object to a function and use that object asthis. Ifdog.bark()usesthis.nameto return"George is barking",dog.bark.call(giraffe)would return"Geoffrey is barking"(assuming your giraffe is named Geoffrey)..call()and.apply()have the same result; the difference is in the signature (.call()takes a list of args;.apply()takes the object and then an array of args). Mnemonic (from CodePlanet): “Call is for comma (separated list) and Apply is for Array.” - Constructor Invocation Pattern: If you create a new object with a constructor function by invoking that function with
new(new Dog), thenthis(when using the methods that exist on that constructor’s prototype on that new object) will refer to that new object.
Here’s where my understanding gets a bit fuzzy—I’d like to review these two points a few more times:
- You can attach
.bind()to a function to create a new “bound” function that uses the object you pass to.bind()as itsthis. Solet giraffeBark = dog.bark.bind(giraffe)will mean that callinggiraffeBark()returns"Geoffrey is barking". - Why is
thiscomplicated? When we pass a callback function, we’re not executing that callback. The callback function is run when the function that calls the callback is run. The execution environment is not always what you would expect, which is whythiscan change.
Day 34
On Friday, we started exploring Node. We’d used the node repl before to experiment with JavaScript from the command line and run simple scripts, but we hadn’t covered much more beyond “okay, now type node into your command line. Okay, you’re good to go!”
We started with a quick overview of the difference between working in Node and working in the browser: both are JavaScript runtime environments. Browsers include APIs for interacting with the DOM; Node includes APIs for interacting with the server and the file system.
From there, we started using the Node file system methods to read from and write to files. We were working with a script that takes two optional command line arguments: the file to read, and the file to write. If the write file isn’t provided, the script writes to /dev/stdout, which was initially described to us as “the terminal/console.log() in node.” If a dash (code>-) is given instead of a file to read, the script reads from stdin. Time for me to have a Capital M Moment with the command line. I kept running variations on this script, like so:
node lib/copy-file.js data/infile.txt outfile.txtThis works as expected: the contents of data/infile.txt get copied to outfile.txt)node lib/copy-file.js data/infile.txtAgain, as expected: the contents of data/infile.txt get written to the console (in Node, the Terminal)node lib/copy-file.js - outfile.txtThis is where things got confusing. The dash means I want to read from stdin, which I currently understand as “the Terminal,” which I process as “the command line.” But…where, exactly? I try this:node lib/copy-file.js - outfile.txtAnd get nothing—as in, I have to forcibly exit out of node because it’s waiting for an argument it’s never going to get.node lib/copy-file.js - outfile.txt data/infile.txtSame thing. In this case, “data/infile.txt” is the fifth command line argument, which the script isn’t looking for/expecting.data/infile.txt node lib/copy-file.js - outfile.txtAn error from bash this time:-bash: data/names.txt: Permission denied
At this point, I can’t think of any other permutations, so I raise my hand and ask for clarification and am reminded about pipes, which are used to pass the output of one command to another command as input.
I try data/infile.txt | node lib/copy-file.js - outfile.txt and get another error from bash (this time with more detail):
-bash: data/names.txt: Permission denied
SyntaxError: Unexpected end of input
at Object.parse (native)
at /Users/Rebekah/wdi/trainings/node-api/lib/copy-json.js:44:17
at FSReqWrap.readFileAfterClose [as oncomplete] (fs.js:380:3)
I’m told I have to use cat to read the the contents of data/infile.txt: cat data/infile.txt | node lib/copy-file.js - outfile.txt. It works!
And I am SO CONFUSED.

I know that cat reads files. But I ALSO know that our script takes a file path—not the contents of that file—and then uses node’s fs module to read that file. From where I’m sitting, it looks like we’re reading the file twice.
(Are you ready? Here’s where the Moment happens.)
I’m confused because I don’t understand stdin/stdout. I’m still thinking of them as “the command line” or “the Terminal.” My mental image of what happens when I run cat data/infile.txt | node lib/copy-file.js - outfile.txt is that it’s the same as running node lib/copy-file.js "all the contents of data/infile.txt" outfile.txt.

I was so very wrong.
(I’m obviously still learning this, so guidance on this particularly is welcome in the comments, and I’ll do my best to update with any corrections.)
Stdin is a file handler or a stream, not a floating, headless mass of whatever you gave it. When I type cat data/infile.txt, I’m reading the contents of data/infile.txt into stdout, which the | then picks up and uses as stdin. I’m not sending the contents of data/infile.txt—to my script as the infile argument. It helped me to think about it as copying data/infile.txt to a new pseudo-file called stdout (and then to stdin), and giving “stdin” to my script instead of “data/infile.txt.” The script can then read the contents of stdin in the same way it can read the contents of data/infile.txt.
(This has been A Moment with Bash.)
None of that was actually the point of the lesson, which was to teach us that Node (unlike plain old JS or jQuery) can interact with the file system, which is pretty cool. It also served as a segue for learning about callback hell and Promises, which we talked about after a quick detour:
.@jrhorn424 just treated us to a dramatic reading of https://t.co/J6PhqWx7GS and ??? @GA_boston #javascript #pbj
— RebekahHeacockJones (@rebekahredux) October 7, 2016
After a round of applause, we spent some time talking about what we should take away from this article. My own favorite response is this one:
This thread by @captainsafia on engineering / learning / tool proliferation is excellent. ? ? ? https://t.co/N0tNXELREn
— RebekahHeacockJones (@rebekahredux) October 5, 2016
But we also talked about the importance of getting the job done and of learning how to focus your energy (and on what). Someone also made the point that the PB&J dude has clearly never been in a grocery store before, and a huge part of GA is, effectively, taking us on lots and lots of trips to the grocery store—we might not know every botanical detail about the tomato, but we know that you don’t need a tomato to make a PB&J, so we’re already, like, eight steps ahead of this guy.
(Lost? It’s worth reading the article, and also the original article about learning JS in 2016. I also really like this response from Addy Osmani: “first do it, then do it right, then do it better.”)
Entering the Promised Land
On to promises. When ES6 came out, I remember reading an article on Medium about promises as part of a larger effort to educate myself about JavaScript, generally speaking. At the time, it was over my head—it was one of those articles that you struggle through because you don’t know what most of the code means and can’t yet conceive of a useful situation for this particular feature.
I’m not sure I’m *that* much clearer on Promises now, but I’m getting closer. Here’s my key takeaway so far:
Promises get you out of callback hell: they help you organize asynchronous code in a more linear way, so it’s easier to read and understand.
The rest is mostly details:
- Promises can be pending or settled. Settled promises can be fulfilled or rejected.
- Promises can only settle once. When they are settled, they are either fulfilled or rejected, but they can’t switch or resettle.
- When you write a promise, the promise’s “executor” takes two functions as arguments:
resolveandreject. The executor usually does something asynchronous (read a file, for example), then, when that work is finished, calls eitherresolve(if it’s successful) orreject(if there’s an error).resolvefulfills the promise and passes whatever data you give it to.then, which takes a callback that executes with that data.rejectrejects the promise and passes the error you give it to.catch, which takes a callback that executes with that error. - Both
.thenand.catchreturn promises, so you can keep chaining.thens and.catches together.
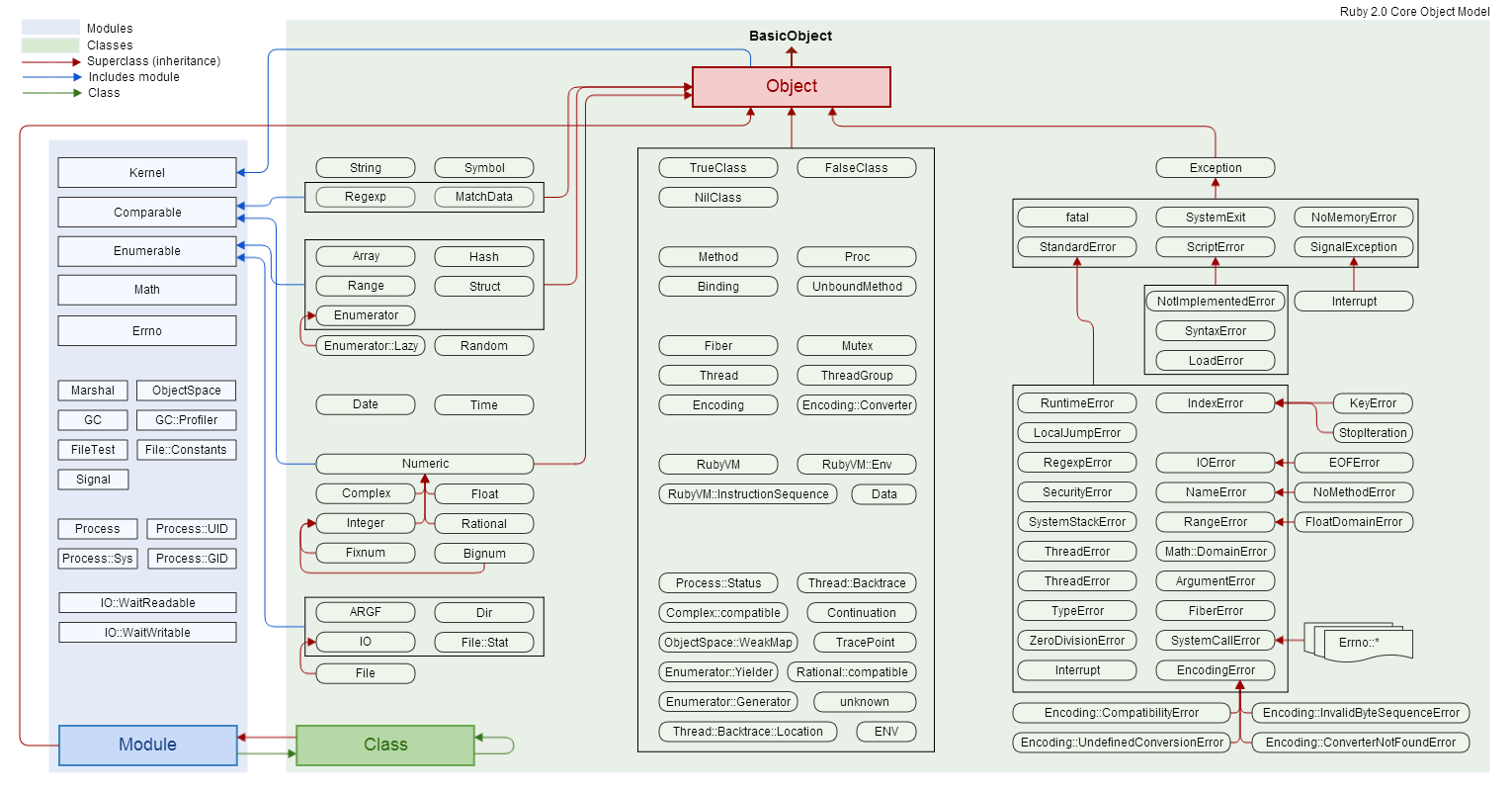
I found this diagram, from the MDN docs on Promise, helpful:
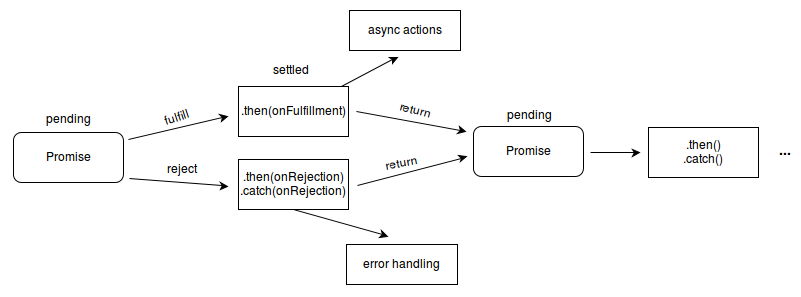
We spent some time “promisifying” scripts that used callbacks, focusing specifically creating “wrapping functions” in Node to use promises instead of callbacks. The emphasis was on avoiding these common mistakes:
- Not returning something from
.then(unless the.thenstatement its the last thing in the chain). If you mess this up, data won’t continue to propagate down the chain. - Not calling
resolveandrejectin the executor somewhere. - Not handling errors (if you don’t, your promise will fail silently).
- Executing a callback (i.e.,
.this(doStuff(data)).this(doStuff)). - Treating AJAX like a promise.
$.ajax()is not a promise.
$.ajax() returns a jqXHR object, not a promise.
As we work more with Node, it sounds like promises are going to be a Big Deal. At the end of last week, they didn’t feel intuitive, but after our homework over the weekend and class yesterday and today, I’m starting to feel a bit better about them. Onward!





{kind=link}