Monday was “Computer Science Day,” which put me squarely in one of my happy places. One of my favorite things in all of Boston is the Bean machine at the Museum of Science, which illustrates the central limit theorem (specifically, the law of normal distribution, aka a bell curve):
Searching & sorting algorithms (which, along with data structures, were the primary topics of the day) tickle that same space in my brain, and come with even more fun videos. Some of my favorite resources for learning about those algorithms, and by extension Big O notation and time/space complexity:
For the data structures portion of the day, we split into groups and each researched a single structure, then presented to the class. My group had linked lists, which are really fun to draw on the board (but maybe not as much fun as tries). Some good resources for learning about these:
The Wikipedia articles on the major types we covered (lists (including primitive arrays, stacks, and queues), linked lists, associative arrays, trees, graphs, and tries) are pretty good. Wikipedia also has an extensive list of data structures.
Days 45-47
"Just a sliver" of the web dev tools & technologies that my @GA#WDI cohort gets to choose from for independent study this week! pic.twitter.com/w06H4ykvDJ
We kicked off Tuesday morning with a giant brainstorming session. The prompt: what technologies and related issues have we not yet covered? It was a long list, and not nearly exhaustive. The goal was to provide starting points for our next assignment: a 15-minute presentation on a topic of our choosing.
This was fun. And overwhelming. And fun. My brain jumped immediately to things I’ve worked on or heard about at Berkman—digital security, Internet censorship (which one colleague chose for her presentation—I was excited to point her to the OpenNet Initiative and Internet Monitor!), Elasticsearch, Kibana, PGP/GPG. I decided to go a completely different direction for my presentation, though, and chose to talk about setting up a code blog with Hugo.
I’m a little behind (only now writing about Week 10 of 12, even though I finished the program in mid-November), but I’ve been doing my best to blog about the code I’m writing and the concepts I’m learning since starting the Web Development Immersive program. I think it’s one of the best things I’ve done for myself as a developer. I’m not always as clear or concise as I’d like to be, but going back through my notes, attempting to distill concepts, and giving myself a second chance to dig into anything that was confusing or particularly intriguing the first time around has helped me retain information, get feedback from others inside and outside of the program, and test my own understanding.
Why Hugo, specifically? Mostly because I’m getting a bit frustrated by WordPress’s bloat and would like to see if I can make the experience of blogging and browsing a bit faster. Jekyll was my first thought, given the size of the community (huge), its connection to GH Pages (which I’ve used for the last four of my public projects), and its use of Ruby (a language I’d like to get better at), but Hugo won me over for its speed argument alone, given that I’d like to port over this blog, which has over a decade’s worth of content. I haven’t yet gone through the process of exporting all of my content to markdown/comments to Disqus and importing them into a Hugo site, but it’s on my to-do list. In the meantime, I put together a quick presentation/tutorial about how to get started with a very basic portfolio site (above) and managed to spark interest in a couple of classmates, which was exciting.
Day 48
I don’t have enough exclamation points to convey my excitement about CLIENT SIDE ROUTING!!!! One of my frustrations throughout the program has been that all of our single page apps only handle/offer a single URL. Want to share a Go Bag packing list with a friend? Nope. Want to send around your Happening event invitation? Nope. Finally getting my hands on (one of) the (many) tools to solve this problem felt so good.
Some basics, if you’re unfamiliar with client side/front end routing: A lot of people are building “single-page applications” these days, which load data dynamically, behind the scenes, as the user interacts with them. The page is never reloaded in the web browser, which makes the user experience a bit faster/more seamless. Because you’re only working with a single web page, you also only have (by default) a single URL. You can check out my packing list app Go Bag for an example of this—logging in, signing up, creating a packing list, editing items, and viewing different lists all happens at https://rhjones.github.io/go-bag/. This is a bummer: what if you want to share a list with a friend? Or send them directly to the sign up page? Or (wait for it) use the back button in your browser? None of this works “out of the box” with a single page application.
Enter: client-side routing, which solves this problem by mapping different parts of a single page web application (like a single packing list, or the view that lets you create a new list, or the log in form) to different URLs. Suddenly, you can bookmark URLs! Share them! Go back and forth between them using the buttons in your browser! It’s like having your single page application cake and eating it, too.
There are larger front-end frameworks that will handle this for you, but we dipped our toe in the water using Router5. We started with a simple HTML page with three divs and a nav bar with three matching links. Each link was tied to an event handler that, when a user clicked the link, would add/remove a “hidden” class to the appropriate divs to “swap out” the desired content. Along the way, the URL never changed.
Using Router5, we refactored this code to instead define a series of routes that matched the previous links and register a series of URL paths based on the internal anchor links. Clicking on one of these links now uses the navigate method of Router5 to navigate to a specific route (i.e., change the URL and execute code associated with that route). We also defined a middleware function that is executed on each transition between routes. This function takes care of adding/removing the “hidden” classes to display the content associated with each route. Ta-da! Functional, shareable URLs that map to specific pieces of a single page JavaScript application.
The goal here was to demonstrate, very simply, how client side routing works and to familiarize us with the concept of associating specific view states with different routes in preparation for working with Ember, which we covered in Week 11. Ember uses Router.js, not Router5, but the principles hold.
The third project for General Assembly was a group project. Each group received a prompt and roughly five days (including the weekend) to execute on it, starting Friday night on Week 8.
Our prompt:
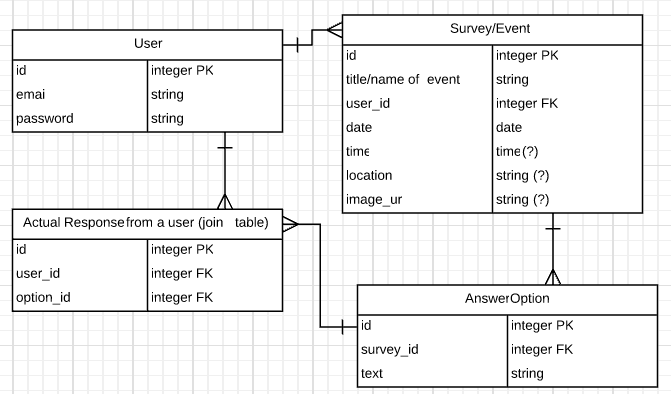
Make an app that can be used to create custom surveys (for instance, asking “what should we eat for lunch today?” or “On a scale of 0-5, how well did you understand what we just learned?”) and collect the responses on a dashboard for that particular survey.
Data Modeling
One of my group members (thanks, KTab!) suggested that we build an online invitation tool instead—the underlying principles (ask a question, collect responses from different users) are the same, but the premise felt a little more fun. We drew up a quick ERD in LucidChart (which is becoming my favorite tool for data modeling) and were feeling pretty good about it:
So pretty! See all those beautiful tables? and fields? and carefully documented relationships?
That’s about when we remembered we were required to use MongoDB & Mongoose instead of a SQL database. (Other requirements: use Express to build a RESTful API, built a JS-based client app to consume data from that API, include user authentication, include all CRUD actions, write user stories, build wireframes, use git/GitHub as a team.)
Awkward. Mongo doesn’t have tables or relationships or models. Mongoose lets us add models and relationships (-ish), but there are still no tables.
We attempted to convert our relational model into a rough sketch that approximated something more document-friendly:
User {
_id,
email,
password,
}
Survey {
user_id,
_id,
title/name,
date,
time,
location,
image_url,
options: [
{ id, text },
{ id, text },
]
}
// less sure about this
Response {
option_id,
user_id
}
This more or less attempts to map our tables onto documents. Which, as far as I can tell, is rarely the best approach: trying to convert a relational data model for use in a NoSQL database seems like it only leads to heartache.
On Friday evening, our group had a long talk with our instructional team about our model, in which they attempted to convince us that what we should be storing as a response—instead of links to an option id and a user id—is a full copy of an event/survey, with the options array replaced by whatever the user chose for their answer. And we could forget
Cue all the feelings of ickiness about data duplication and potential out-of-sync-ness and, again, data duplication. Data duplication is also called data denormalization: this is good for reducing the number of queries needed; it also reduces number of write operations needed: you only need to write to one document to affect lots of data. But still: THIS FEELS SO DIRTY.
Part of the argument was that storing a full copy of an event/survey (which I’ll refer to as an “event” from here on out) inside of a response means that a user’s response to a question isn’t affected if the event owner changes the event. In both our initial relational model and the model above, an event owner could change the question associated with an event from something like “Are you coming?” to “Do you eat hamburgers?” A vegetarian reader who had RSVP-ed yes could suddenly find themselves having committed to eating meat. Storing an entire copy of the event as it was when the user responded inside of the user’s response means that a response and a question are never out of sync. This is a good thing!
What’s not as good: events and responses are never reliably in sync. (I’m intentionally setting aside the pros and cons of letting a user edit an event after people have already responded—this is weird functionality that has a lot of potential issues, both technical and social.) This means that response data can’t as easily be counted and presented.
After some back and forth, we decided to go with this approach. We rewrote our data outline to look like this:
User {
_id,
email,
password,
username,
}
Event {
_id,
_owner (references user id),
name/title,
location,
date,
startTime,
endTime,
description,
questions: [
{
text: Are you coming?,
options: [yes, no, maybe]
},
{
text: Which dinner option do you want?,
options: [fish, chicken, pasta]
}
]
}
RSVP {
_id,
_event (references event id),
_owner (references user id),
questions: [
{
text: Are you coming?,
answer: yes
},
{
text: Which dinner option do you want?,
answer: pasta
}
]
}
I’m still pretty uncomfortable with this. A couple of things I’m still working out:
Does copying (“serializing”) an event into a response make sense? Duplicating event data (things like title, location, etc.) means that displaying a single RSVP requires only a single query to the RSVPs collection, rather than a query that accesses both the RSVPs and the events collections. It also means that if a user changes anything about an event—updates the description, for example—that change isn’t automatically propagated over to each corresponding RSVP. It would be possible, I think, to write code that updates each RSVP when an event is updated, but a) that’s potentially database-intensive in a way that feels dirty to me; and b) that kind of defeats the point of serializing data in the first place.
Does allowing a user to edit an event after it has received RSVPs make sense? I can see arguments for an against this. We currently have a warning message on the edit page that lets event owners know that changing data related to questions & answers might affect the responses they see, but this is a human (not a technical) way of handling things, and it doesn’t feel entirely sufficient.
If a user does edit an event and change the associated questions/answers, what happens to someone who’s already responded? Does their data “count”? Should their answers still be reported to the event owner/as part of the event? We’re currently looping through the questions/answers on the event and tallying up matching answers in any associated responses, which means that only responses matching the current version of the event data get counted. Again, this doesn’t feel like the optimal approach.
In general, tallying response data feels less efficient: we have to locate an event, locate all of the responses, and then inspect the data within the event to find the current questions and answer options. We then have to compare that data to each response and evaluate whether there’s a match. In a relational database, we’d need more queries, but it would be much easier to get counts. We’re also doing all of this based just on string comparison, rather than on database ids, which makes me…sort of itchy. (This is related to, but not entirely the same as, my question about editing events, above.)
We’re currently leaning on Mongoose’s .populate method to retrieve all of the RSVPs that belong to an event when we get an event. After reviewing the code, it looks like I for some reason also set up a virtual property on the Event model that gets all of the RSVPs. I’m pretty sure this is redundant/not actually doing anything—adding this to my list of future revisions. Also, we’re populating the RSVPs for an event in order to do two things: 1) check RSVPs and do some filtering so a user isn’t given the option to re-RSVP to something they’ve already responded to; and 2) tally up responses. It looks like we could be using Mongoose’s field name syntax to only grab the user ids and the question/answer data, which would help streamline things, which makes me happy.
This is less “a thing that makes me uncomfortable” and more “a thing I’d like to do in the future,” but right now, we’re not handling different question types very well: responses are set up to only hold a single answer for a question, and questions in an event have an array of possible answer options. This doesn’t work well for things like open-ended questions, multiple answer questions, etc. I’d like to come back to this and think about how to better handle a range of question types.
We got our API up and running over the weekend (nothing like a Bagelsaurus-fueled Saturday marathon coding session) and met with the instructors again on Monday for feedback. They brought up another possible approach we hadn’t considered: setting up a separate “statistics” controller in Express to handle population and data tallying. This would involve making a query to the events collection for the event, then making a secondary request to a stats route (which would then presumably query the RSVPs collection?), and *then* building out whatever data display we wanted. This isn’t super efficient, but it is clean: what I took away from the conversation is that it’s a bad idea to have the event & RSVP models talk to each other inside of the model (like we are with the virtual property)—we want to avoid having a “junk drawer” model in the app that essentially pulls in data from all of the other models. To be totally honest: we considered this idea for a minute and decided to forge on without implementing it because the API was functional, it was Monday, and we had three days to build the client app.
After our feedback meeting, we took away a list of to-dos related to our API:
Make sure to delete all RSVPs associated with an event before deleting the event. My understanding is that because we’re using Mongo and Express, the only way to do this is manually—there’s nothing like Rails’ dependent: :destroy.
Build a way to show all events to a user that don’t belong to the user AND to which a user hasn’t RSVPed (a list of all RSVP-able events for a user).
The first of these was fairly trivial: in the destroy method in the events controller, first remove/delete all associated RSVPs, then delete the event.
The second of these was more difficult. We attempted this:
Which did not get us what we want: you can’t directly query populated data like this. On the advice of our instructors, we ended up finding all events where the owner is not the current user, then using .foreach() to loop through each rsvp for each event and determine whether the current user owns any of them (whether the current user has already rsvped for the event). The logic was sound here, but it took us longer that I want to admit to process that MongoDB ids are not strings. Doing a comparison—even a loose one—between rsvp._owner and req.currentUser._id was getting us nowhere until one of my groupmates (thanks, Jaime!) suggested that we call .toString() on the ids. Success!
Now that we’re not under the wire, I’m realizing that Query#populate might have gotten us closer to what we wanted, and Query#select the rest of the way, without having to loop through all of the data. I’d like to go back and try this—if it works, it would definitely be a cleaner approach.
Client-side App
With our API all squared away, we spent Tuesday and Wednesday working on the front end. This was fairly straightforward—it didn’t differ too much, structurally speaking, from the front ends we had all built for our second projects.
The two most difficult pieces were both tied to questions and answers: figuring out how to count up and display response data, and figuring out how to correctly display and gather question & answer data from forms. (In Boston, GA offers a “get form fields” JS script that extracts data from form fields and, based on the name attributes of each field, formats it as a JavaScript object. This is usually sufficient, but I couldn’t quite manage to figure out how to name our inputs in order to end up with an array inside of an object that also contains a property that’s a string, and have of that end up in another array that’s inside of an object. I eventually ended up with input fields for the answer options that are named event[questions][0][options][], but I haven’t yet worked in the ability in Handlebars to generate multiple questions (event[questions][1][options][], etc….)
We started with a pretty low bar, initially: event creators would have no say over questions and answers. Instead, all events would have a single question (“Are you coming?”) with three potential answers (“Yes”, “No”, and “Maybe”). We wrote our forms (using Handlebars templates) and our “tallying” code to handle this case, and then decided to expand incrementally: first by writing more flexible tallying code that would match up the event’s question and answer options against the responses, and then by allowing event creators to edit a single question with three required answer options.
The next step—on my list of to-dos—is to give event creators the power to add multiple question possibilities with variable numbers of answers. Our API is set up to handle this, but the front end doesn’t yet have the flexibility to add/remove the necessary form fields to expand/contract the set of questions and answers.
A third interesting and kind of tricky piece was handling date and time formatting between Mongo, form fields, and display. I ended up writing a tiny library of functions to handle this for us, and then—during our presentation—learned about Moment.js. Next time!
Aesthetics
Our design came down to the wire a bit—we prioritized, I think rightly so, API and UI functionality over shine. That said, we managed to get in a few custom colors/fonts and a background image for the home page. This is definitely on the “come back to” list—we have a long list of ideas (uploading header images for events! changing an invitation’s color scheme based on those images! offering different invitation designs! fully responsive design! among other things) we’d love to implement going forward, but as of Wednesday evening, we had a fully functional product with an acceptable design.
We spent Friday split into our new (and final!) squads, practicing interview questions with the instructors, with our course producer, on CodeWars/HackerRank/Interview Cake, and with a group of GA alumni who came in during the afternoon and ran mock whiteboard interviews with us. It’s not exactly news, but technical interviewing is a totally different skill than building web applications. I think I like the data side of things the best (see: this post), but my current sense of the industry is that to move decisively in that direction, I’ll need to get much better at “traditional” computer science skills and concepts, including algorithmic thinking, pattern recognition, and math. In particular, I’d like to improve my ability to draw upon this knowledge quickly during interviews. On the advice of a friend, I’m working my way through Cracking the Coding Interview and spending as much time as I can on HackerRank.
Friday was intense, especially coming off of project week, but it was also fun. I’ve always loved tests, and the questions I was asked—which ranged from “design a Monopoly game” to “what is a closure” to “what’s your favorite programming language and why?” to good old fizzbuzz—stretched my brain in different directions pretty rapidly, which was good practice.
Can we all agree that we’re collectively going to ignore the fact that we just wrapped up week 10, and I’m only now getting around to writing up week 8?
For those who are new to Mongo: it’s a NoSQL database. NoSQL databases are generally better at scaling and overall performance. They’re more flexible, and they’re (allegedly?) better suited to agile workflows, where you might be making adjustments to your database schema as often as every couple of weeks. Instead of storing data in rows and tables, they store data in documents and collections of documents—essentially, as JSON that’s fairly agnostic about what it contains. What they’re not: relational. I don’t yet have personal experience working with non-relational data, and I think Sarah makes a convincing argument that most data is relational, but I’ve been trying to come around to the possibility that Mongo might be the right choice for some things. Todd Hoff makes some good points; I’m still mulling over these.
After Mongo, we talked about Node: Node is a JavaScript runtime that lets you do things like interact with the file system or write a server. Typical uses of Node rely pretty heavily on asynchronicity, which let us build on what we learned last week about promises. We started by using Node’s HTTP module to make a request to a Node-based echo server, using both traditional callbacks and then* promises.
*LOLOLOLOLOL promise joke.
Day 36
On Tuesday, we examined the echo server we made requests to on Monday. Key things a Node server needs to do:
create server instance
pass at least one callback to do work
receive request
do any necessary processing
make response
send response
close connection
Rails did all of this for us, but in Node, we have to write it all. All of this server code is what’s behind Express, which is a library/framework that adds (among other things) routing capabilities to Node servers. We touched quickly on Express and promised to come back to it later in the week.
Day 37
Actually working with Mongo came next: we ran through basic CRUD functionality from the command line, then moved on to Mongoose, which lets you define data models in Mongo and felt a little bit like having some of my sanity restored. Quick cheat sheet:
rails : node
active record : mongoose
ruby object : js object
sql : mongodb
Mongoose also gives you the ability to set up “virtual” properties on your data models, which are properties you calculate on the fly based on real, non-virtual properties on those models. For example: you can define a virtual property on a Person model to calculate a person’s age based on the current date and on that person’s birthday, which is stored in the database.
We also came back to Express and wrote a simple Express API. This felt good and familiar—I’ve seen this process in Laravel, in Rails, and in Express, now, and I’m starting to feel like I’m gaining a little bit of fluency with the process of setting up routes and controllers across different languages/frameworks.
Day 38-39
We spent part of Thursday morning going over Agile and Scrum to prep for our upcoming group project. I’ve heard about Agile a few times—at an HUIT summit a couple of years ago, when I was trying to figure out how best to work with various teams in my last job, and at a Boston Ruby meetup earlier this month. I’m a total process and organization geek, and I’m excited at the prospect of working within an agile framework up close.
The rest of the week was devoted to learning how to upload files to Amazon Web Services S3 using Express and Multer. We started by writing a command line script (along the way, I learned about the shebang: #!), then moved on to writing a simple web app that would accept a file and a comment about it, upload the file to AWS S3, and store the URL and the comment in a Mongo DB.
I’d like to come back to this—we didn’t end up needing to use it in our group project, but I have a couple of ideas for how to incorporate this, and I’d love to implement them at some point.
We got our project prompts on Friday evening and headed straight into group project work for most of Week 9. I’m working on that post now, so stay tuned for my notes-slash-ravings on data modeling for a survey builder application in Mongo/Mongoose!
The first three days of Week 7 were devoted to our projects: Monday and Tuesday were work days, and Wednesday was for presentations. If you want a blow-by-blow of project two, I wrote up my daily dev log here.
While working on my project, I had an interesting conversation with one of the GA instructors about the API we use for our first project (Tic Tac Toe). I built a feature for my version of the game that gets all of a user’s prior game history when they log in and goes through each game that’s marked as “over” to calculate whether the game was a win, loss, or tie. These stats are tallied and displayed at the bottom of the window, and are updated as the user plays new games.
It doesn’t take a long time to calculate these stats—the logic isn’t terribly complicated, the entire package of data is pretty small, and, seriously, how many games of Tic Tac Toe could one person ever want to play? But I’ve been thinking about how much easier this process would be if, at the end of a game, we could just store the winner (or “tie”) on the server. That would let us avoid re-calculating the winner for each game just to get a stats counter.
After I made my pitch, I got a quick introduction to memoization, which is when you store data that takes some time to calculate on a server, so you can retrieve it rather than recalculating it each time. The key point we covered: memoization without validation can be dangerous. It would be easy to mark a player as the winner without the game being over and/or without that player having won. Also, for Tic Tac Toe, it’s not really a big issue, as it’s not that computationally expensive to re-tally the stats each time (it’s also, as was pointed out to me, a good exercise for us). Another point: memoization involves a tradeoff between time (to recalculate) and space (to store extra data on the server). Lastly: this is still a bit above my paygrade as someone relatively new to the field. But it’s cool to be thinking about!
Another couple of things that came up during project presentations that I want to remember:
A handful of people recommended Bootsnipp for examples of good uses of Bootstrap for specific UI elements (things like testimonials or five-star ratings).
One person made the best wireframes using Balsamiq. I experimented with creating my wireframes in LucidChart, since I had already sketched out my data relationship model there, but I ended up drawing them by hand, which was faster and easier. But those Balsamiq wireframes…they were gorgeous.
It’s a bad idea, optimization-wise, to include an entire font in your project if you’re only going to use a couple of characters (for a logo or an icon, for example). It slows down load times, especially on mobile; it’s better to make a .png of what you need and use that instead. Guilty as charged—going to try to do better next time.
Day 33
After a quick review of distributed git workflows (our next project is a group project), we jumped back into JavaScript to talk about this.
Though I think (hope) I’m starting to get a better handle on it. We talked about the “four patterns of invocation” (described by Douglas Crockford in JavaScript: The Good Parts):
Function Invocation Pattern: If you call a function in the global namespace, this refers to the global object. In the browser, this is the window; in Node, you’ll get the node object. Note that this is not true if you’re using 'use strict'—strict mode disables this from pointing to the global object; instead, it points to undefined.
Method Invocation Pattern: If you call a function on an object (dog.bark()), this refers to the “host object” (the object on which you called the method). Inside of bark(), this will be dog.
Call/Apply Invocation Pattern: You can use .call() and .apply() to pass an object to a function and use that object as this. If dog.bark() uses this.name to return "George is barking", dog.bark.call(giraffe) would return "Geoffrey is barking" (assuming your giraffe is named Geoffrey). .call() and .apply() have the same result; the difference is in the signature (.call() takes a list of args; .apply() takes the object and then an array of args). Mnemonic (from CodePlanet): “Call is for comma (separated list) and Apply is for Array.”
Constructor Invocation Pattern: If you create a new object with a constructor function by invoking that function with new (new Dog), then this (when using the methods that exist on that constructor’s prototype on that new object) will refer to that new object.
Here’s where my understanding gets a bit fuzzy—I’d like to review these two points a few more times:
You can attach .bind() to a function to create a new “bound” function that uses the object you pass to .bind() as its this. So let giraffeBark = dog.bark.bind(giraffe) will mean that calling giraffeBark() returns "Geoffrey is barking".
Why is this complicated? When we pass a callback function, we’re not executing that callback. The callback function is run when the function that calls the callback is run. The execution environment is not always what you would expect, which is why this can change.
Day 34
On Friday, we started exploring Node. We’d used the node repl before to experiment with JavaScript from the command line and run simple scripts, but we hadn’t covered much more beyond “okay, now type node into your command line. Okay, you’re good to go!”
We started with a quick overview of the difference between working in Node and working in the browser: both are JavaScript runtime environments. Browsers include APIs for interacting with the DOM; Node includes APIs for interacting with the server and the file system.
From there, we started using the Node file system methods to read from and write to files. We were working with a script that takes two optional command line arguments: the file to read, and the file to write. If the write file isn’t provided, the script writes to /dev/stdout, which was initially described to us as “the terminal/console.log() in node.” If a dash (code>-) is given instead of a file to read, the script reads from stdin. Time for me to have a Capital M Moment with the command line. I kept running variations on this script, like so:
node lib/copy-file.js data/infile.txt outfile.txt This works as expected: the contents of data/infile.txt get copied to outfile.txt)
node lib/copy-file.js data/infile.txt Again, as expected: the contents of data/infile.txt get written to the console (in Node, the Terminal)
node lib/copy-file.js - outfile.txt This is where things got confusing. The dash means I want to read from stdin, which I currently understand as “the Terminal,” which I process as “the command line.” But…where, exactly? I try this:
node lib/copy-file.js - outfile.txt And get nothing—as in, I have to forcibly exit out of node because it’s waiting for an argument it’s never going to get.
node lib/copy-file.js - outfile.txt data/infile.txt Same thing. In this case, “data/infile.txt” is the fifth command line argument, which the script isn’t looking for/expecting.
data/infile.txt node lib/copy-file.js - outfile.txt An error from bash this time: -bash: data/names.txt: Permission denied
At this point, I can’t think of any other permutations, so I raise my hand and ask for clarification and am reminded about pipes, which are used to pass the output of one command to another command as input.
I try data/infile.txt | node lib/copy-file.js - outfile.txt and get another error from bash (this time with more detail):
-bash: data/names.txt: Permission denied
SyntaxError: Unexpected end of input
at Object.parse (native)
at /Users/Rebekah/wdi/trainings/node-api/lib/copy-json.js:44:17
at FSReqWrap.readFileAfterClose [as oncomplete] (fs.js:380:3)
I’m told I have to use cat to read the the contents of data/infile.txt: cat data/infile.txt | node lib/copy-file.js - outfile.txt. It works!
And I am SO CONFUSED.
I know that cat reads files. But I ALSO know that our script takes a file path—not the contents of that file—and then uses node’s fs module to read that file. From where I’m sitting, it looks like we’re reading the file twice.
(Are you ready? Here’s where the Moment happens.)
I’m confused because I don’t understand stdin/stdout. I’m still thinking of them as “the command line” or “the Terminal.” My mental image of what happens when I run cat data/infile.txt | node lib/copy-file.js - outfile.txt is that it’s the same as running node lib/copy-file.js "all the contents of data/infile.txt" outfile.txt.
I was so very wrong.
(I’m obviously still learning this, so guidance on this particularly is welcome in the comments, and I’ll do my best to update with any corrections.)
Stdin is a file handler or a stream, not a floating, headless mass of whatever you gave it. When I type cat data/infile.txt, I’m reading the contents of data/infile.txt into stdout, which the | then picks up and uses as stdin. I’m not sending the contents of data/infile.txt—to my script as the infile argument. It helped me to think about it as copying data/infile.txt to a new pseudo-file called stdout (and then to stdin), and giving “stdin” to my script instead of “data/infile.txt.” The script can then read the contents of stdin in the same way it can read the contents of data/infile.txt.
(This has been A Moment with Bash.)
None of that was actually the point of the lesson, which was to teach us that Node (unlike plain old JS or jQuery) can interact with the file system, which is pretty cool. It also served as a segue for learning about callback hell and Promises, which we talked about after a quick detour:
But we also talked about the importance of getting the job done and of learning how to focus your energy (and on what). Someone also made the point that the PB&J dude has clearly never been in a grocery store before, and a huge part of GA is, effectively, taking us on lots and lots of trips to the grocery store—we might not know every botanical detail about the tomato, but we know that you don’t need a tomato to make a PB&J, so we’re already, like, eight steps ahead of this guy.
(Lost? It’s worth reading the article, and also the original article about learning JS in 2016. I also really like this response from Addy Osmani: “first do it, then do it right, then do it better.”)
Entering the Promised Land
On to promises. When ES6 came out, I remember reading an article on Medium about promises as part of a larger effort to educate myself about JavaScript, generally speaking. At the time, it was over my head—it was one of those articles that you struggle through because you don’t know what most of the code means and can’t yet conceive of a useful situation for this particular feature.
I’m not sure I’m *that* much clearer on Promises now, but I’m getting closer. Here’s my key takeaway so far:
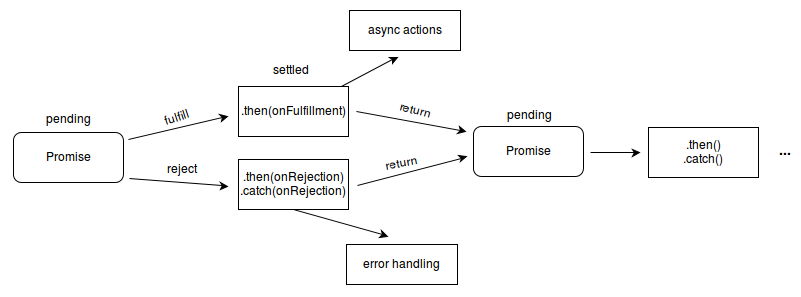
Promises get you out of callback hell: they help you organize asynchronous code in a more linear way, so it’s easier to read and understand.
The rest is mostly details:
Promises can be pending or settled. Settled promises can be fulfilled or rejected.
Promises can only settle once. When they are settled, they are either fulfilled or rejected, but they can’t switch or resettle.
When you write a promise, the promise’s “executor” takes two functions as arguments: resolve and reject. The executor usually does something asynchronous (read a file, for example), then, when that work is finished, calls either resolve (if it’s successful) or reject (if there’s an error). resolve fulfills the promise and passes whatever data you give it to .then, which takes a callback that executes with that data. reject rejects the promise and passes the error you give it to .catch, which takes a callback that executes with that error.
Both .then and .catch return promises, so you can keep chaining .thens and .catches together.
We spent some time “promisifying” scripts that used callbacks, focusing specifically creating “wrapping functions” in Node to use promises instead of callbacks. The emphasis was on avoiding these common mistakes:
Not returning something from .then (unless the .then statement its the last thing in the chain). If you mess this up, data won’t continue to propagate down the chain.
Not calling resolve and reject in the executor somewhere.
Not handling errors (if you don’t, your promise will fail silently).
Executing a callback (i.e., .this(doStuff(data)).this(doStuff)).
Treating AJAX like a promise. $.ajax() is not a promise.
$.ajax() returns a jqXHR object, not a promise.
As we work more with Node, it sounds like promises are going to be a Big Deal. At the end of last week, they didn’t feel intuitive, but after our homework over the weekend and class yesterday and today, I’m starting to feel a bit better about them. Onward!
Our second project for General Assembly was to build an API using Rails and then build a single-page JavaScript application for interacting with it. We had solid technical instructions, but the content was totally up to us—for me, this is always the hardest part. I love making things, but inventing them isn’t my forte.
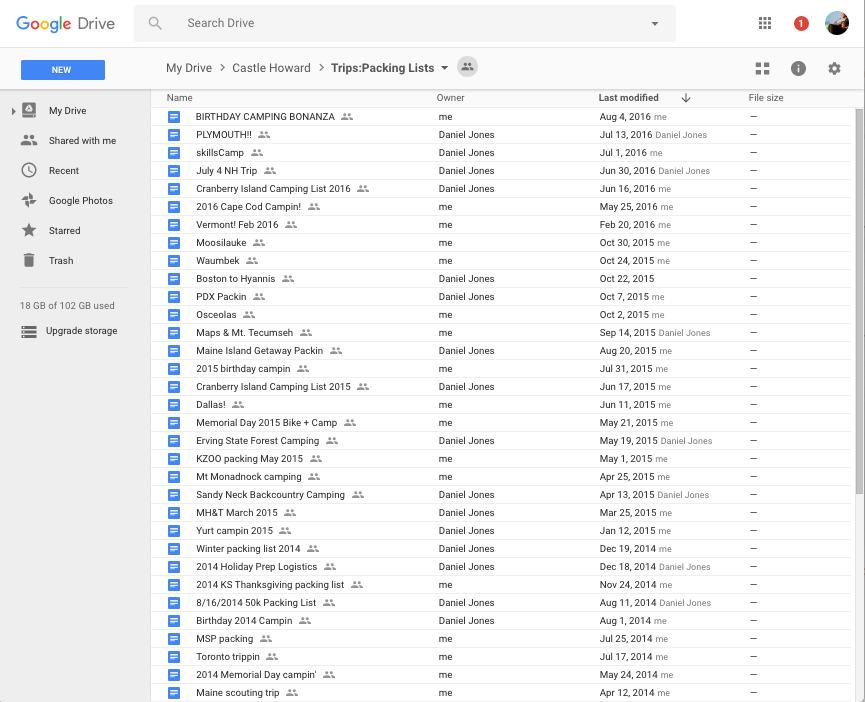
Luckily, I had a problem in need of solving. See this?
Those are packing lists. Dozens of them, and that’s only counting trips I’ve taken with my partner in the past couple of years. I’ve also made lists in Simplenote, scribbled them on the backs of envelopes or the margins of research papers, and—worst—forgotten to make lists and ended up in Toronto without a toothbrush.
It’s not a gigantic problem, but it was enough to spark Go Bag, a packing list app for people like me.
Quick links, in case you want to skip the chatter below and go straight to the code:
During this project, I experimented with keeping a “dev log”—quick notes on what I did each day. It was a good way to track my progress and make note of anything that stumped me/new things I discovered. I kept it in Simplenote, and kept my running to-do list at the bottom, which made it easy to move tasks up into the log one at a time as I worked on them and gave me a space to offload ideas for the future and things I didn’t want to forget (like “double check that that button still works” or “write documentation”). A++ would do again.
9/23
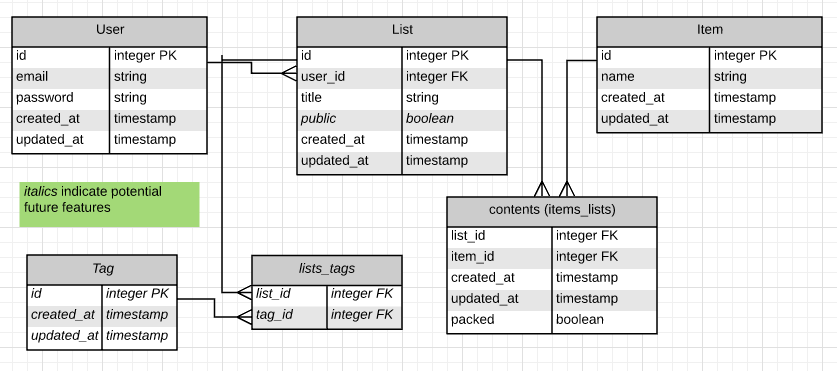
I started by sketching out a data model in LucidChart:
9/26
We were given a template for a Rails API that included a users resource and authentication. Starting there, I used Rails’ scaffolding to generate models / migrations / routes / controllers / serializers for my lists, items, and contents, then set up the relationships among everything.
9/28
On 9/26 and 9/27 we learned about automated testing using RSpec. It was the best. I decided to try to backfill in tests, but I got tripped up with authentication and, in the interest of time, decided to move on.
9/29
This was our first official project day. I spent the day:
Writing and testing curl scripts for every action I wanted to perform with my API.
Protecting lists, items, and contents by having their controller classes inherit from the provided ProtectedController class, which checks to make sure the user is authenticated before providing access to the resources.
Using current_user to make sure users can only access their own packing lists.
Sketching wireframes.
Building out forms and API calls from the front end for authentication, based heavily on my Tic Tac Toe app. I was pretty excited to be able to refactor my log in function(s)— I was previously using two separate log in functions, one to handle “regular” logging in, and one to handle automatic log ins for users who had just signed up. I was able to condense this into a single function, which felt great.
Starting to separate HTML into Handlebars templates. For this project, we were given the same client-side template as we were for the Tic Tac Toe games. One of the more confusing/frustrating pieces of that project was figuring out how and when to hide/show different DOM elements, and how to make sure that what was displaying on the page always matched up with what was on the server. My game appends things on the page and then sends data to the server, which works functionally but also a) is a lot of steps, and b) leaves open the potential for the client and the server to get out of sync. Working with Handlebars made the concept of “re-rendering” click for me—I can grab data, feed in into a template, and replace everything currently on the page or in a specific section with the product of that template. Figuring out how to split things up and making sure I had the appropriate elements in the DOM to target for replacement/re-filling was a bit tricky, but once I got the hang of it, I felt like I could work more smoothly and cleanly.
9/30
Kept working with Handlebars.
Signed up for a Heroku account and deployed my API. It took me a while to figure out that my global ~/.gitignore file had been set (as part of GA’s Installfest) to ignore all secrets.yml files, which hold the environment variables for secret keys. (I had even checked ~/.gitignore_global, which is the sample file name GitHub uses when talking about global gitignore files, but hadn’t looked inside of ~/.gitignore. Oops.) This caused issues trying to set secret keys on Heroku, and a friend and I spent a significant chunk of the morning working through this. I ended up forcibly adding the file to my repo, which felt scary and bad (but worked!), before one of the instructors jumped in and explained the ~/.gitignore issue.
After that, I went back to Handlebars and discovered the hard way that you can’t register event handlers to DOM elements that aren’t on the page when it initially loads. Whoops! I went back and fixed that by registering events on elements that *do* exist, then moved on to building functionality that allows authenticated users to create lists and add items to a list.
One of the pieces of flair I really wanted for this app was the ability to type a potential packing list item—say, a toothbrush—into an input field and have an autocompleted list of potential items to choose from pop up. This felt like smoother UX than checking off items from a super long list on a page, and it tied in with my desire to avoid having a different toothbrush in the database for each user.
I decided to use the Devbridge jQuery-autocomplete library for this. I spent the rest of the day getting this to work, with a couple of challenges/steps:
I needed to implement search functionality in my API for autocomplete to work.
Despite the fact that the library claims to allow you to pass in headers, I saw multiple issues filed on the repo from people who couldn’t successfully pass an auth token through in their API call. I couldn’t get this to work either, so I ended up unprotected the index/show methods for my items controller in order to get autocomplete to work.
The library makes the API call for you, but it sends back a JSON string instead of a JavaScript object. It took me more time that I want to admit to realize this. Pro tip: are your property keys surrounded by quotation marks when they’re normally not? You’re probably working with JSON!
The library wants your potential autocomplete suggestion data to be formatted in a very specific way, so I needed to write a function to transform the data coming back from my API.
Towards the end of the day, I had a fully functional autocompleting input field. Typing in “to” would offer “toothbrush” and “toothpaste” and “Tootsie rolls” (assuming all three of these existed in the items table already) as possible options. Success! From my perspective, this is the coolest part of my project. It feels polished in a way that not much else I’ve built yet does, and it adds functionality—it helps suggest things to users that they might forget and offers a tiny bit of serendipity (typing in “s” to get to “sweater” will give you a list of options that includes “swimsuit,” which might help you make use of the hotel pool in Boston in February). It also, I think, looks nice.
Restraining myself from using hyperbole and exclamation points in my commit messages but in my heart they mostly read “DID MAGIC!!!!!"
I was feeling pretty impressed with myself, but that balloon popped almost immediately when I realized I hadn’t thought carefully enough through the UX workflow to know how to build the next piece, where choosing an item from that pool of suggestions lets a user add it to a list, and typing in something that’s not in the pool of suggestions creates a new item and then adds it to the list. I spent a few minutes hashing this out, referencing Avocado (a list-making app for pairs of people) heavily in the process. At the end, I had this:
form will have a hidden input element for the list id
enter an item, save
after saving, display another item input field so the user can add another item
focus first on items that exist in db
figure out later how to add a new item using same UI (ultimately decided: if item exists already, save a “contents” association between the list and the item. If it doesn’t, first save the item, then save the contents association)
That gave me enough to work on starting on Saturday morning.
10/1
I got single item addition working, then moved on to letting users add multiple items in succession. This involved redrawing the list after saving the item, which meant going back to my serializers to make sure I was passing sufficient data through in order to be able to access a list’s title and id plus all of its items’ ids and names. I also added some validation to the Contents model so that a list can’t contain more than one of the same item.
After this, I realized that I hadn’t done enough testing after splitting up my HTML into different templates, and I had broken more of my click handlers than I realized, particularly around authentication. Bug fixing time!
Since I was working with authentication anyway, I decided to build user profile functionality, where logging in gets a user’s email and lists and renders the user’s list titles (including links that let the user edit each list individually) on the page. This gave me some code I could reuse when switching to and from different views/states while authenticated, which was an added bonus.
I fixed some more click handlers, played around with the default order of lists and items coming back from Rails, and fixed a bug that was popping up when a user tried to add an item (say, “toothbrush holder”) that starts with the name of another item (“toothbrush”). This turned out to be fairly simply, and involved using an option that comes with the jQuery-autocomplete library that is activated when you “invalidate” input (in other words, when you keep typing after already filling the input with a valid option from the list of suggestions).
10/2
I started Sunday with lots of deleting: items from lists, and lists from a user’s account. I decided not to offer item delete functionality through the client—I didn’t set up my data model in such a way that the items a user adds are associated only with their accounts, and I didn’t want users to delete items that would then be (surprise!) removed from other users’ lists. This was a deliberate decision, as I wanted the things a user adds to their list that I haven’t, as the maker of the app, already thought of to be available to other users. For example: if I seed the items table with “insect repellant” but someone else adds “bug spray” to their list, I want other users to be able to find and add “bug spray” as well. There seemed to me to be enough value in that collectively generated set of items that I didn’t want to hide it from users.
There are cons to this approach that I haven’t quite figured out yet. The first is privacy. If you add “Helga’s Wellbutrin” or “surprise birthday present for Alistair,” those items are available for everyone to see, which is a bad thing. The second relates to usefulness: as Fran, I don’t care about or want my options cluttered with Helga and Alistair’s stuff. When I was presenting Go Bag, I talked a bit about this, and I think my next step is to enable a seeded list of items available to all users, but confine new items to specific users’ accounts. Each user will be able to see the seed list plus the items they’ve added, but not the items anyone else has added. Another step past this would be to let users suggest new items for the seed list, and create an admin account with the power to approve/deny these requests. “Bug spray” would get added, but “lolBUTTS” would be visible only to troll1997@butts.butts.
After building the client-side deletion features, I added a checkbox to mark an item within a list as “packed” and updated the API to send back items in a list ordered first by unpacked vs packed, and then, within those groups, with the most recently updated items first. Given that I’m re-rendering the contents of a list each time they change, this means that clicking the checkbox next to an item to pack it will move it toward the bottom of the list, to the top of the section of packed items. Unchecking it will move it back to the top of the list. Since I’m getting all list items (“contents” in my data model) through the lists serializer, I realized I don’t need dedicated index or show methods for contents, so I removed those from the ContentsController class.
At this point, I decided to get what I had up on GitHub pages and make sure it worked with my deployed API. After I set the CLIENT_ORIGIN on my deployed API to my GitHub pages URL, everything worked as expected.
I moved back to the client side of things and moved error messages out of console.log() statements and into the UI. I also added some lightweight validation on lists, so that a user can’t have two lists with the same title.
At this point, I felt like I had all of the client-side functionality that I absolutely needed in order to submit a working project. This freed me up to start working on design, which I both like (shiny things!) and find trying: inventing a design from scratch while simultaneously writing HTML/CSS feels a bit like building the airplane while it’s already in the air. I could solve this problem by putting together better, full-fledged mock-ups with art and typography, but a) that’s not practical on the timeline we have for GA projects, and b) I’m still mourning my loss of access to the Adobe Creative Suite, and I haven’t yet bothered to acquire/teach myself replacement software.
I spent the next few hours working with Handlebars templates, SCSS, stock photography, and Google fonts. I took a few small breaks to build tiny bits of actual functionality: for example, ensuring that clicking on the app’s logo in the upper left would load the default home page for visitors but the correct user’s profile for authenticated users.
Once I had the home page and authentication forms looking mostly how I wanted them to look, I gave myself a reward and built a list title editing feature (in case your New Hampshire camping trip gets rained out and you end up going to the Catskills instead) and—this was super cool—the ability to clone lists. I find myself duplicating my lists in Google docs all the time so that I can tweak an existing list for a new trip instead of starting with a blank slate. In Rails, I used the deep_cloneable gem to clone a record (list) with its associations (contents/items). I didn’t have to write much code for this, but it felt like absolute magic. A couple of tips:
Cloning uses a POST request, which expects data. All the data you need is already in the database (which is why you’re cloning in the first place), so you can send an empty data object along with your request to fix the HTTP/1.1 411 Length Required error.
I had set up validation so that lists can’t have the same title. To make sure the cloned record validates, I had to edit the title before saving—I prepended “copy of” so that it would be clear to users what had happened.
At this point, it was Sunday evening, and rather than jumping into building new stuff, I decided to work on documentation for my API. I had Willow’s tweet in my head while I was typing:
Be the adult you wish you had around when you were a child.
Write the documentation you wish you had when you started on this project.
I know not everyone gets as excited as I do about rules and guidelines, but to me, this is a thing of beauty.
10/3
On Monday, I went back to styling. Such SCSS. So typing. Cool things I learned:
You can use word-wrap: break-word; to break up a really long string of characters (say, an email address like rebekahheacockjones@gmail.com?) so it doesn’t, for example, run off the screen on mobile.
It’s frustrating to work with Handlebars templates + CSS + JS. Moving things around in Handlebars will (inevitably, again) break your functionality, and relying on the same classes for styling and functionality is starting to feel more and more precarious. I’m curious about best practices here—I know at least one company that has separate classes for CSS-related things and for JS-related things, which makes your markup a bit longer/clunkier but sounds kind of attractive at this point.
I grumble about this, but I’m pretty happy with the way the UI turned out:
Desktop
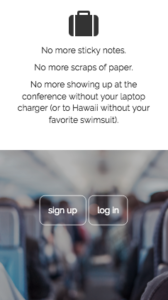
Go Bag
About Go Bag
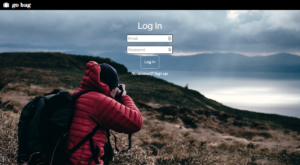
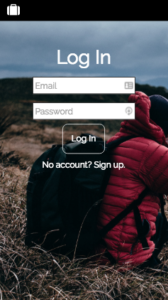
Go Bag: log in
Add a list
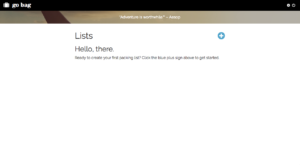
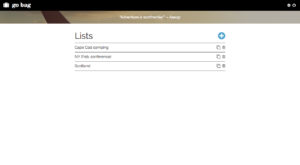
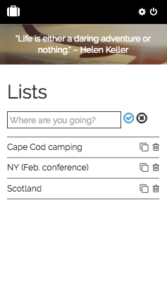
Lists
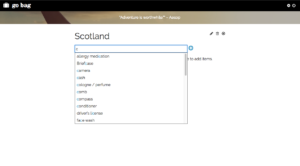
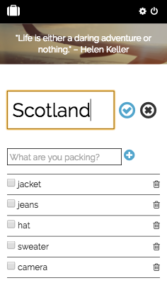
Add an item using autocomplete
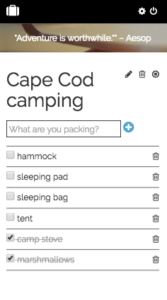
Single list
Mobile
Go Bag (mobile)
Go Bag: about (mobile)
Go Bag: log in (mobile)
Lists (mobile)
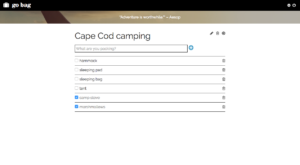
Edit a list title (mobile)
Single list view (mobile)
I spent the rest of the day writing up documentation for the front-end repo (a shorter version of this, plus Agile user stories, wireframes, and a list of dependencies), putting together a seed list of items, and tweaking my API documentation.
10/4
Last project day! I spend the morning cleaning up (taking out console.log() statements; organizing and refactoring to the best of my ability) and adding a few extra touches: a favicon, a “loading” icon that replaces the “Sign Up” and “Log In” button text while the form is processing, and adding smooth internal scrolling when you click the “learn more” link on the home page.
I sent the app to a few friends and family for “beta testing,” and my sister discovered a bug when clicking the home button immediately after adding a new list—I needed to re-fetch the user profile data before re-rendering the profile view. (Thanks, Katie!)
At this point, I had half a day left, so I decided to venture back into RSpec. I started by reading through a bunch of articles on testing Rails APIs with Rspec. Many of them recommended using two additional tools, both from Thoughtbot: Shoulda Matchers and Factory Girl.
I was writing tests for one of my models, and I already had set up / tear down steps written to create and delete instances of that model for testing, so I decided to skip Factory Girl for now and experiment with Shoulda.
After this, I ran into an issue with authentication inside of a test that I still haven’t figured out (hoping to work one-on-one with an instructor soon, as even after some back-and-forth and trying out multiple methods of handling authentication tokens within the test, I’m still getting an “HTTP Token: Access denied” error). It didn’t put me off of automated testing, though—I’m determined to get this working. The first “real” CS course I ever took was CS50, and our first problem set included tests for the C programs we were writing. Seeing those green smiley faces was SO. COOL. I want my code to do that—to not only work the way I expect it to work, but to self-verify that it works the way I expect it to work, and to do that in a way that communicates clearly to other people who work on the same code what should happen and what, if anything, is broken.
10/5
Presentation day! Once again, the random presentation order put me at the end, which gave me all morning and all of lunch to be nervous.
I used the same tactic I used last time, of pulling up a bunch of tabs with things I wanted to make sure I talked about. I overdid it a bit because I wasn’t sure how long each thing would take, so I only made it through half of the things on my list before the timer beeped, and I felt like I was rushing things and not actually making the points I wanted to make. Overall, though, it went okay—I got some good questions about my approach to testing (all the curl scripts, plus some general sadness about not working with RSpec as much as I wanted to) and—I was kind of surprised by this!—people seemed really interested in how I implemented the random travel quote that’s displayed at the top of the page when you log in. (It’s an array of strings; I pick a random one and send it to the Handlebars template each time the profile is rendered.)